Realmagic
锐盟半导体
入职时间:2025.9.26
离职时间:2025.12.22
上班时间:周一到周五
公司介绍
公司是一家初创企业,依托于锐盟半导体(类似于子公司),主要做的是面向小学 1 - 3 年级辅导相关的具身智能产品,产品形态是一个台灯,内置了摄像头、麦克风、扬声器、投影仪等硬件,可以通过语音和图像识别技术与学生进行互动,帮助学生完成作业和背诵课文等任务
实习产出
1. 主 agent 重构 —— 编排器 + Workflow + 工具化
1.1 原始架构和痛点
原本的完整链路:
客户端通过 websocket 发送请求到主 agent 对应接口 —— 后端解析音频或图片 —— 主 agent 创建主任务并识别意图处理逻辑 —— 根据意图通过 http 自调用对应的子 agent 并修改状态 —— 子 agent 创建子任务执行逻辑 —— 子 agent 通过 websocket 直接返回执行结果并修改状态
主 agent 直接全权负责路由的决策,它会从 shortMemory(未引入 redis)读取用户上下文,获得当前的状态,状态包括 idle、pre_agent_name、doing_agent_name,主 agent 不负责子 agent 执行完逻辑后的状态修改,需要子 agent 自行将状态修改回聊天 agent 的 idle
主 agent 调用 qwen3-max 模型,以批改作业为例,输出的 JSON 格式如下:
{
"recognition": "识别到用户想要批改作业",
"intention": "用户意图是获取作业批改结果",
"decision": "切换到批改状态并调用批改 Agent",
"execution": "调用homework_correct Agent",
"Agent_calling_protocol": [
"homework_correct",
"learning_progress"
],
"new_state": "correct_homework"
}
状态更新主要通过提取 new_state 字段,更新 shortMemory,再触发实际状态变化来完成,即 idle -> pre -> doing -> idle 的状态机
任务管理器主要通过异步方式调用子 agent 的接口来完成任务的创建和执行
项目采用的是 FastAPI,业务模块都在 modules 目录下,包括 agents、asr、user 等,shared 作为公共模块,存放了配置管理、数据库、api 和中间件等目录,每个 agent 都有自己的服务逻辑和路由接口,具体分层为 api、service、repository、prompt、utils 和 errors
主 agent 和子 agent 都在 src/modules/agents 目录下,每个 agent 都有自己的路由和服务逻辑,agent 列表:
- chat_companion —— 聊天 agent
- homework_correct —— 作业批改 agent
- homework_solver —— 作业解题 agent
- homework_summary —— 作业总结 agent
- homework_tutor —— 作业辅导 agent
- learning_companion —— 主 agent
- learning_progress —— 学习进度 agent
- learning_scheduler —— 学习计划 agent
- learning_status_supervisor —— 学习状态监督 agent1
- recitation —— 背诵 agent
主 agent 通过 ACP(Agent Calling Protocol)协议来管理子 agent
背诵业务流程示例:
用户: "我要开始背古诗了"
↓
[主Agent决策]
→ 识别意图: 背诵古诗
→ 调用Agent: recitation
↓
[recitation执行]
1. 获取背诵内容
- 从学习计划中获取今日背诵任务
- 生成标准答案
2. 对比分析
- 将用户输入与标准答案进行对比
- 计算背诵正确率
- 识别错误位置和类型
3. 错误模式识别
- 查询历史: error_pattern 表
- 判断某个错误是否重复犯
- 更新错误频次
4. 生成记忆方法
IF occurrence_count >= 2:
→ 调用 VL 模型生成记忆技巧
5. 反馈生成
- 首次错误: "加油,再试一次!"
- 重复错误: "这个字已经错2次了,记忆方法: ..."
↓
[保存记录]
- 表: recitation_history
- 表: recitation_error_pattern
- 用于周报、月报分析
↓
[返回用户]
{
"accuracy": 95,
"errors": [
{
"position": "第2句",
"expected": "疑是",
"actual": "移是",
"tip": "记忆方法..."
}
]
}
由于主 agent 直接负责路由决策和状态管理,导致了主 agent 和整体架构存在以下问题:
- 性能差
- 实际体验时延较高,简单的输入也需要主 agent 对不同场景做判断决策,响应等待时间长
- agent 之间互相 HTTP 自调用,无微服务、部署相关准备
- 可维护性差
- 主 agent 代码臃肿,逻辑复杂,难以维护和扩展
- 主 agent 的 service 文件达上千行,新增一个场景要在同一个函数里加好几段逻辑
- 扩展性
- 新增一个 agent / 业务流程时,需要改主 agent和多个子 agent 的调用逻辑
- 业务场景逻辑不清晰,各个子 agent 的功能边界模糊、职责未工具化,难以对新需求进行快速迭代
- 难以灵活编排不同场景下的细分逻辑,无法根据不同场景灵活调整子 agent 调用顺序和条件,无法并行调用多个子 agent
- 状态与上下文管理混乱
- 主 agent 和子 agent 都需要修改状态,容易出现状态不一致的问题
- 上下文信息分散在 shortMemory 和各个 agent 中,难以统一管理,状态的定义也未能满足复杂场景需求
- 会话状态、学习进度、task_id 分散在本地缓存、数据库多个地方,出了 bug 很难排查
- 主 agent 路由决策准确度难以保障和调优,由于主 agent 需要同时处理路由决策和业务逻辑,导致模型负担过重,难以专注于路由决策
- 可观测性差
- 一次完整学习流程涉及多个接口,很难一眼看出某个孩子从开始写作业到生成报告中间经过了哪些步骤
- 日志管理混乱,难以追踪和分析问题,错误处理不统一,有的场景超时重试,有的直接抛 500,大量冗余日志重复产生,难以定位问题根源
1.2 重构目标和整体方案
- 引入编排器(Orchestrator)
- 路由决策、业务逻辑编排和具体业务实现彻底解耦,意图识别和路由决策分离
- 对外暴露 /api/orchestrator/process 接口作为后台系统唯一入口,接收客户端通过 websocket 发起的请求,并通过编排器统一返回 websocket 响应
- 对内负责状态管理(引入 Redis)、路由决策(引入 Guardrails)和工作流调用
- 增加置信度,降低模型不确定性对路由的影响
- 重新定义状态模型,建立统一会话状态模型与状态存储,支持跨轮对话、场景切换与恢复
- 引入工作流(Workflow)
- 面向业务,不同场景内部有子状态,通过状态机推进逻辑流程
- 进行具体的业务流程编排和细节处理,通过 tools 层调用不同工具
- 可扩展,将业务流程从 agent 内部抽离,新增业务场景时只需定义工作流状态机和节点调用
- agent 工具化
- 业务功能工具化,子 agent 不同功能、机械臂动作、表情等均拆分成独立的工具,每个工具都是在某个节点上做的一次原子操作
- 各个 agent 只暴露工具化的 API 接口,一个接口只负责某个细分的业务功能,如 LLM 具体调用与原子工具执行
- tools 层是对于 agent 暴露的接口和硬件相关工具的统一封装
- 统一响应结构、日志与 trace_id,提升可观测性与问题定位效率
调用链路:
- 客户端通过 websocket 调用编排器的 process 接口
- 编排器调用输入解析器解析音频和图片
- 编排器读取当前状态
- 编排器调用主 agent 识别意图
- 编排器将主 agent 返回结果给 Guardrails 执行真正路由决策
- 编排器根据决策调用不同业务场景下工作流
- 工作流按业务状态机调用不同子 agent 的工具执行业务逻辑
- 编排器接收结果更新状态和上下文
- 编排器返回结果给客户端
Client (WebSocket)
│
▼
/api/orchestrator/process ← 统一入口
│
├─→ InputParser.parse() ← 解析输入(音频/图片/文本)
│
├─→ StateStore.get() ← 获取Redis状态(自动验证、跨天重置)
│
├─→ agent_caller.classify_intent() ← 主Agent意图分类(快速,只分类不决策)
│
├─→ GuardrailsEngine.decide() ← 护栏决策(基于评分做路由)
│ ├─ 输入合法性检查
│ ├─ pending TTL 维护
│ └─ 生成 GuardDecision: continue/switch/exit/reject
│
├─→ 执行决策
│ ├─ switch → 切换场景 → WorkflowExecutor
│ ├─ exit → 退出到 chat
│ ├─ continue → WorkflowExecutor
│ └─ reject → 拒绝请求
│
├─→ WorkflowExecutor.execute_scene_workflow()
│ ├─ ChatWorkflow (idle/clarify/handoff_wait)
│ └─ RecitationWorkflow (idle/listening/done)
│
├─→ ResponseBuilder.text/voice/card() ← 构建统一响应
│
└─→ WebSocket 推送 + HTTP 返回
预期重构后完整架构图:
1.3 关键设计和实现细节
1.3.1 编排器 (OrchestratorService)
文件位置: src/core/orchestrator/orchestrator_service.py
职责:
- 统一入口,协调所有组件
- 调用主 Agent 进行意图分类
- 通过 Guardrails 做路由决策
- 调用 WorkflowExecutor 执行业务逻辑
核心函数:
async def process(self, user_id, session_id, input_data, trace_id) -> OrchestratorResponse:
# 1. 解析输入
context = await InputParser.parse(input_data)
# 2. 获取会话状态(自动验证、跨天重置)
current_state = await self.state_store.get(user_id, session_id)
# 3. 主 Agent 意图分类(只分类,不决策)
intent_result = await self.agent.classify_intent(user_input, active_scene, ...)
# 4. Guardrails 决策
decision = await self.guardrails.decide(user_input, agent_intent, current_state)
# 5. 执行决策(switch/continue/exit/reject)
if decision.action == "switch":
await self.state_store.update_scene(user_id, session_id, new_scene)
return await self._process_in_scene(...)
# ...
1.3.2 护栏引擎 (GuardrailsEngine)
文件位置: src/core/orchestrator/guardrails/guardrails_engine.py
设计理念:
- 信任模型评分:主 Agent 给出 0-100 分,Guardrails 映射为置信度
- 职责分离:主 Agent 只分类 + 评分,Guardrails 做校验 + 决策
- 场景切换谨慎:中置信度时设置 pending,需二次确认
置信度映射:
@property
def confidence_level(self) -> Confidence:
if self.score >= 75:
return Confidence.HIGH # 高置信度:直接执行
elif self.score >= 50:
return Confidence.MID # 中置信度:设置pending,等确认
else:
return Confidence.LOW # 低置信度:保守,继续当前
决策逻辑:
| 置信度 | 目标=当前场景 | 目标≠当前场景 |
|---|---|---|
| HIGH | continue | switch(直接切换) |
| MID | continue | 设置 pending_switch,等确认 |
| LOW | continue | continue(保守策略) |
pending_switch 机制:
@dataclass
class PendingSwitch:
target: str # 目标场景
slots: Dict # 槽位信息
age_turns: int = 0 # 已等待轮次(超过3轮自动失效)
- 中置信度识别到切换意图 → 设置 pending
- 下一轮用户确认(HIGH/确认词)→ 执行切换
- 用户高置信度指向其他场景 → 放弃原 pending
- 超过
PENDING_TTL_TURNS=3轮 → 自动失效
1.3.3 状态管理 (StateStore + SessionState)
文件位置:
src/core/orchestrator/state/state_store.pysrc/core/orchestrator/state/session_state.py
统一状态模型:
@dataclass
class SessionState:
user_id: int
session_id: str
active_scene: ActiveScene # chat | recite | homework
scene_state: Dict[str, Any] # 场景内部状态(phase、learning_schedule等)
pending_switch: Optional[PendingSwitch] # 待确认的场景切换
ttl_deadline: Optional[int] # 场景粘滞截止时间
last_intent: Optional[LastIntent] # 上一次意图
last_activity: str # 最后活动时间
SessionState {
"active_scene": "chat | recite | homework", // 当前大场景
"scene_state": { // 当前场景内部子状态
"...": "..."
},
"pending_switch": null | { "target": "..."} , // 是否正在等待用户确认切场景
"ttl_deadline": 1732456789, // 场景粘滞到期时间(可选)
"last_intent": { "intent": "...", "confidence": "HIGH/MID/LOW" }
}
状态管理策略:
| 策略 | 触发条件 | 处理方式 |
|---|---|---|
| 跨天重置 | updated_at.date() != today | 重置到 chat,清空 learning_schedule |
| 超时重置 | 非 chat 场景 + 10分钟无活动 | 重置到 chat,保留 learning_schedule |
| 启动清理 | 程序重启 | 扫描所有 session:* 键,执行验证重置 |
Redis 存储:
- Key:
session:{user_id}:{session_id} - TTL: 24小时
- 上下文历史:
context_history:{user_id},最多保留5条
1.3.4 工作流执行器 (WorkflowExecutor)
文件位置: src/core/workflow/workflow_executor.py
职责: 根据场景分发到对应的工作流
async def execute_scene_workflow(self, scene, user_id, session_id, ...):
if scene == "chat":
return await self.chat_workflow.execute(...)
elif scene == "recite":
return await self.recitation_workflow.execute(...)
elif scene == "homework":
# TODO: 作业场景未实现
return {"success": False, "error": "Homework workflow not implemented"}
Workflow 基本元素:
- node(phase)
- 工作流中的一个具体节点,调用某个子 agent 的某个工具
- step(event, state)
- 这张图在当前 phase 下,用这次用户输入推进一步的执行函数
- edge
- 转移条件,连接不同节点
工作流职责:
- 从 Orchestrator 获取学习计划中的背诵任务
- 调用 Agent 的原子工具(工具内部调用大模型)
- 管理状态转换和业务流程
- 控制硬件(机械臂、LCD)
- 返回响应给 Orchestrator
1.3.5 聊天工作流 (ChatWorkflow)
文件位置: src/core/workflow/chat_workflow.py
状态机:
idle ←→ clarify ←→ handoff_wait
| Phase | 职责 | 下一状态 |
|---|---|---|
| idle | 正常对话,支持工具调用 | clarify(需澄清)/ handoff_wait(有pending) |
| clarify | 意图澄清 | idle / handoff_wait |
| handoff_wait | 等待场景切换确认 | idle(取消)/ 切换场景(确认) |
1.3.6 背诵工作流 (RecitationWorkflow)
文件位置: src/core/workflow/recitation_workflow.py
状态机:
idle → listening → done → idle
| Phase | 职责 | 核心逻辑 |
|---|---|---|
| idle | 初始化、获取材料、判断意图 | 从 learning_schedule 提取背诵任务;调用模型判断是否背诵意图 |
| listening | 执行背诵核心逻辑 | 判断是否背诵内容 → 调用 compare_and_evaluate → 保存历史 → 生成记忆技巧 |
| done | 完成处理 | 保存记录、控制硬件(跳舞/微笑) |
业务规则常量:
PASS_THRESHOLD = 85.0 # 达标阈值
MAX_ROUNDS = 3 # 最大背诵轮次
状态机设计(三个状态):
-
idle: 初始化和模糊输入的统一处理
- 调用模型判断用户输入意图
- 如果是背诵意图:phase更新到listening,生成背诵鼓励内容
- 如果不是背诵意图:生成对用户输入的响应(如建议接下来做什么)
-
listening: 执行背诵业务逻辑(核心阶段)
- 调用模型判断输入是否是实际背诵内容
- 如果是:走正常的正确率比对、错误分类、记忆技巧生成等流程
- 如果不是:phase切回idle,让idle处理后再决定phase
- 正常完成后:phase更新到done
-
done: 完成处理
- 背诵记录写库
- 根据正确率生成背诵复习计划
- phase更新回idle
1.3.7 Agent 调用器 (AgentCaller)
文件位置: src/core/tools/agent_caller.py
职责: 封装对各 Agent 工具化接口的 HTTP 调用
调用方式:
# 通用调用
result = await agent_caller.call("recitation", "compare-and-evaluate", payload)
# 语义化封装
result = await agent_caller.classify_intent(user_input, active_scene, ...)
result = await agent_caller.chat(user_id, session_id, text, context, tools)
result = await agent_caller.compare_and_evaluate(expected_text, user_text)
result = await agent_caller.generate_memory_tips(user_id, errors)
容错机制:
async def classify_intent(...):
try:
result = await self.call("learning-companion", "classify-intent", {...})
return result
except Exception as e:
# LLM API 失败时,返回保守默认策略
return {
"intent": "continue_current",
"score": 50,
"reason": "意图分类失败,默认继续当前场景"
}
1.3.8 主 Agent (learning-companion)
文件位置: src/modules/agents/learning_companion/api/learning_companion_router.py
| 接口 | 职责 |
|---|---|
POST /classify-intent | 意图分类(只分类,不决策) |
接口定义:
class IntentClassificationRequest(BaseModel):
user_input: str
active_scene: str
pending_switch: Optional[Dict[str, Any]]
user_id: int
class IntentClassificationResponse(BaseModel):
intent: str # chat/recite/homework/continue_current/exit_current
score: int # 0-100
slots: Dict
reason: str
1.3.9 聊天 Agent (chat-companion)
文件位置: src/modules/agents/chat_companion/api/chat_companion_router.py
| 接口 | 职责 | 对应 Phase |
|---|---|---|
POST /chat | 正常对话(支持工具调用) | idle |
POST /clarify | 意图澄清 | clarify |
POST /confirm-handoff | 确认场景切换 | handoff_wait |
1.3.10 背诵 Agent (recitation)
文件位置: src/modules/agents/recitation/api/recitation_router.py
| 接口 | 职责 | 内部调用 LLM |
|---|---|---|
POST /analyze-idle-intent | 分析 idle 状态用户意图 | ✅ |
POST /check-is-recitation-content | 判断是否为背诵内容 | ✅ |
POST /compare-and-evaluate | 对比文本并评估(核心) | ✅ |
POST /generate-memory-tips | 生成记忆技巧 | ✅ |
POST /generate-standard-answer | 生成标准答案 | ✅ |
POST /save-history | 保存背诵历史 | ❌ |
1.3.11 统一响应结构
文件位置: src/core/orchestrator/response_builder.py
@dataclass
class OrchestratorResponse:
success: bool
content: ResponseContent # text/voice/card
trace_id: str # 链路追踪
session_id: str
scene: str # 当前场景
phase: str # 当前阶段
suggested_actions: List[str] # 建议下一步
need_tts: bool # 是否需要语音合成
error: Optional[str]
processing_time_ms: int
timestamp: datetime
1.3.12 Orchestrator Dependencies - 依赖注入
提供 OrchestratorService 及相关依赖的注入
Dependencies 说明: 这是 FastAPI 的依赖注入模块,用于:
- 创建和管理服务实例的生命周期
- 提供单例缓存(使用 @lru_cache)
- 解耦组件依赖关系,便于测试和替换
什么是 @lru_cache 和单例?
- @lru_cache 装饰的函数会缓存返回值
- 第一次调用会真正执行函数,后续调用直接返回缓存的结果
- 这样保证整个应用共享同一个实例(单例模式)
编排器API的角色:
- 对外暴露唯一入口
/orchestrate,接收用户输入 - 负责协调意图识别、状态管理、工作流执行
工具调用方式(重要):
- 工作流直接导入使用 tools 模块(如 chat_tools, recitation_tools)
- 不再通过依赖注入传递 AgentToolCaller
- 工具调用额外封装在 tools 层
1.4 重构进度和效果复盘
编排器 —— 工作流 —— 工具化的三层架构已完整落地,只有作业相关 agent 和其对应的工作流未完成,因为我不是写作业相关业务场景的研发人员,但主 agent、聊天 agent 和背诵 agent 的迁移及其对应的工作流均已完整实现,编排器相关组件的开发也已完成,并已在测试环境完成联调和验证
重构后的实际体验时延明显降低,主 agent 代码量大幅减少,业务逻辑清晰,新增业务场景时只需定义工作流和节点调用,极大提升了可维护性和扩展性
原有架构下的路由错误问题也得到解决,聊天和背诵业务场景下的切换不再模糊、混乱和误判,状态更新也更加清晰一致,上下文也得到了统一管理
2. 背诵 agent 完整开发
独立负责背诵 agent 从设计、开发、测试和上线的完整流程,完成了背诵检查、错误分析与记忆强化、复习计划和个性化报告等功能
2.1 场景和目标
服务对象:小学 1 - 3 年级学生及其家长
解决的核心问题:
- 学生背诵古诗文和英语课文时,容易出现错误,缺乏有效的检查和纠错机制
- 学生记忆效果不佳,缺乏科学的记忆优化和复习计划
- 家长难以了解学生的背诵情况,缺乏个性化的背诵报告和总结
主要功能:
- 实时背诵检查与纠错
- 错误分类与针对性记忆优化
- 基于艾宾浩斯记忆曲线的复习计划
- 个性化背诵报告生成
验收标准:
- 背诵场景作为完整独立的业务工作流接入重构后技术架构,由编排器调度
- 背诵检查准确率达到 90% 左右
- 单次调用延迟约 2 - 3 秒
2.2 流程和接口
2.2.1 业务流程
提醒开始背诵 → 背诵检查 → 背诵辅导(有错的地方做提醒) → 如果正确率大于等于 85% 就不需要再次背诵,如果正确率小于 85% 当学生再次背诵,直到大于 85% → 给出鼓励 → 结束(提供家长背诵时间、背诵准确率)
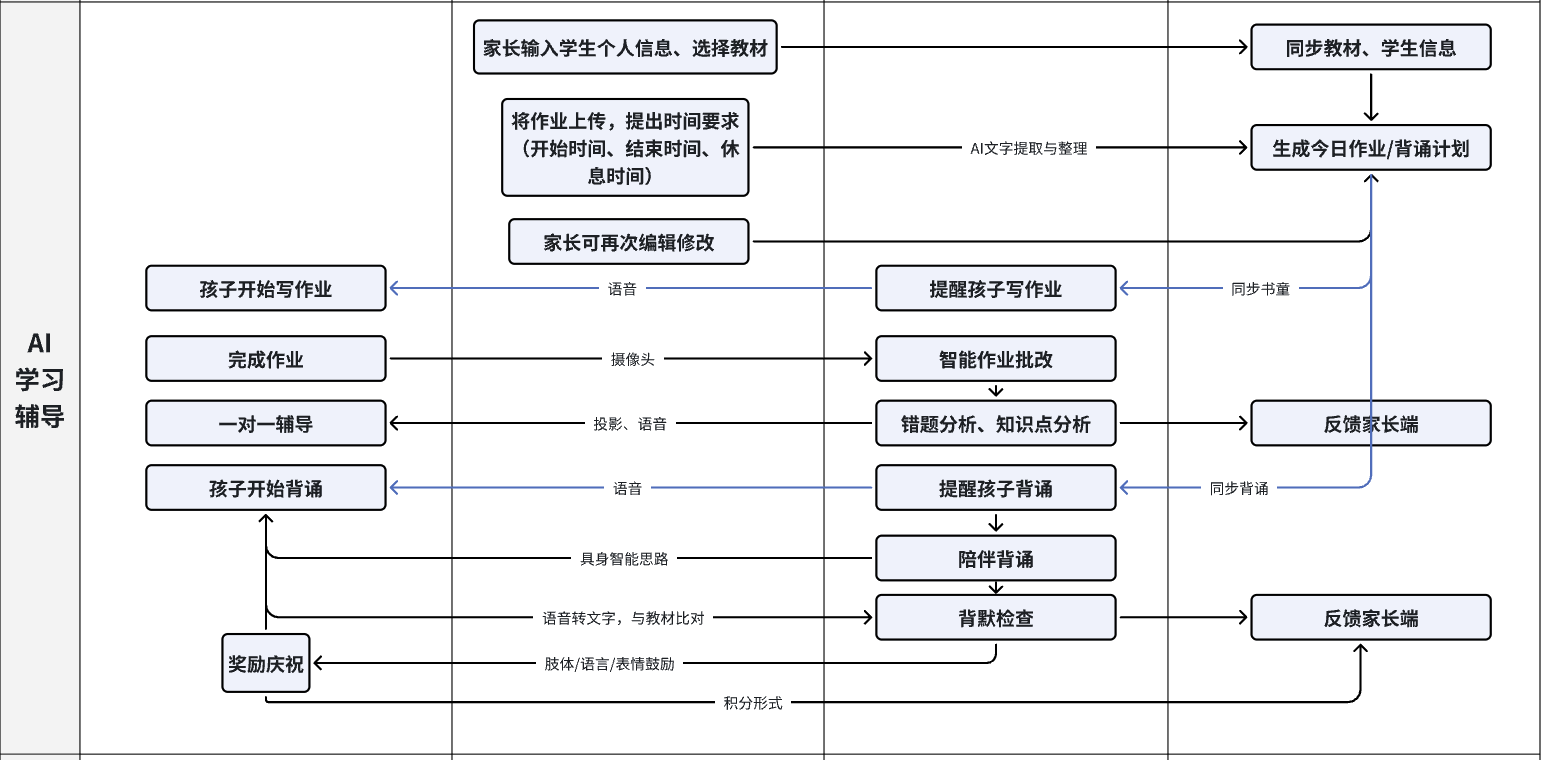
记忆优化:
- 针对性纠错
- 记忆存储:将学生错误分类成高频错误
- 字音错
- 漏内容
- 记混顺序
- 其他
- 优化功能:
- 若同类错误仅出现 1 次:简单提醒正确答案即可
- 若同类错误重复出现(≥2 次):补充错误原因和记忆方法
- 补充 “趣味记忆法”,且内容要短、具象。比如 “字音错” 重复 2 次,除了正确读音,附加 “口诀记忆”(如 “苹果的‘苹’,和‘瓶子’的‘瓶’发音一样哦”
- 记忆存储:将学生错误分类成高频错误
- 记忆曲线复习
- 记忆存储:
- 记录学生每段内容的首次达标时间(如 3 月 1 日背熟《春晓》)
- 后续复习的正确率变化(如 3 月 3 日复习正确率 90%,3 月 7 日复习正确率 82%)
- 功能逻辑:
- 根据“艾宾浩斯记忆曲线”,自动计算下次复习时间(如首次达标后 1 天、3 天、7 天)
- 到点提醒复习
- 若某次复习正确率下降,缩短下次复习间隔
- 记忆存储:
- 生成个性化背诵报告
- 记忆存储:
- 汇总学生日/周背诵数据(今日/本周背诵 5 次,平均正确率 88%)
- 进步/薄弱点(今日/本周英语单词正确率从 75% 提升到 92%,古文背诵仍常错)
- 功能输出:结合数据生成日报/周报,分析学习趋势,总结薄弱点
- 记忆存储:
2.2.2 接口设计
- POST
/api/agents/recitation/run- 同步执行背诵 agent 主流程,即比对、返回正确率/错误/记忆方法等逻辑
- 输入:
input_data: text(学生背诵的内容字符串)、user_id(用户唯一标识符) - 输出:
accuracy、feedback、need_retry等
/api/agents/recitation/run-async- 异步执行背诵 agent 主流程
/api/agents/recitation/report/daily/{user_id, target_date}- 生成并返回指定用户指定日期的背诵日报
/api/agents/recitation/report/weekly/{user_id, target_date}- 生成并返回指定用户指定的截止日期的背诵周报
- GET
/api/agents/recitation/task/{task_id}- 获取背诵主流程任务执行状态和结果
/api/agents/recitation/history/{user_id}- 获取背诵历史记录
/api/agents/recitation/reviews/due/{user_id}- 获取复习计划信息
/api/agents/recitation/run:
输入示例:
{
"input_data": {
"text": "白日依山尽,黄河入海流。"
},
"task_id": 123,
"user_id": 1
}
输出示例:
{
"agent_id": "recitation_99191857",
"user_id": 1,
"accuracy": 50,
"need_retry": true,
"feedback": "准确率50%,前两句很好,但遗漏了第3、4句,完整背一遍试试\n\n漏内容(第2次): 登高望远见山河,不更上怎见一层楼。",
"errors": [
{
"position": "第3-4句",
"expected": "欲穷千里目,更上一层楼。",
"actual": "",
"type": "遗漏"
}
],
"usage": {
"qwen_plus": {
"input_tokens": 828,
"output_tokens": 116,
"cost": 0.0009
}
}
}
run 接口是直接同步执行并返回,run-async 接口是异步执行,通过 task_id 查询执行结果
2.3 数据和状态设计
2.3.1 数据设计
recitation_history —— 背诵历史记录,记录每次背诵的正确/用户输入内容、正确率、是否需要重试、错误详情、模型回复等完整信息
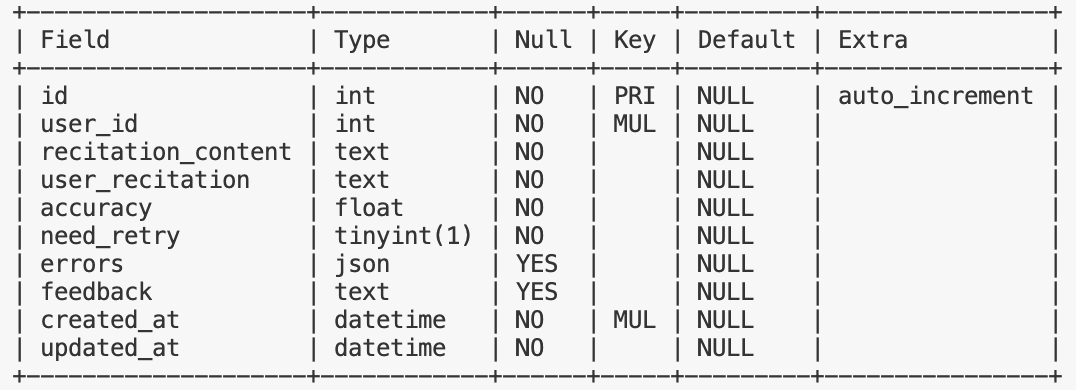
查询指定日期的背诵历史:
针对 user_id 和 created_at 两个字段建立了联合索引,覆盖了 where 条件,查询语句如下:
SELECT * FROM recitation_history
WHERE user_id = ?
AND created_at >= '2025-11-15 00:00:00'
AND created_at <= '2025-11-15 23:59:59';
recitation_error_pattern —— 背诵错误模式记录,记录学生在背诵过程中出现的错误类型、内容、频次和记忆方法,用于后续记忆优化和复习计划制定
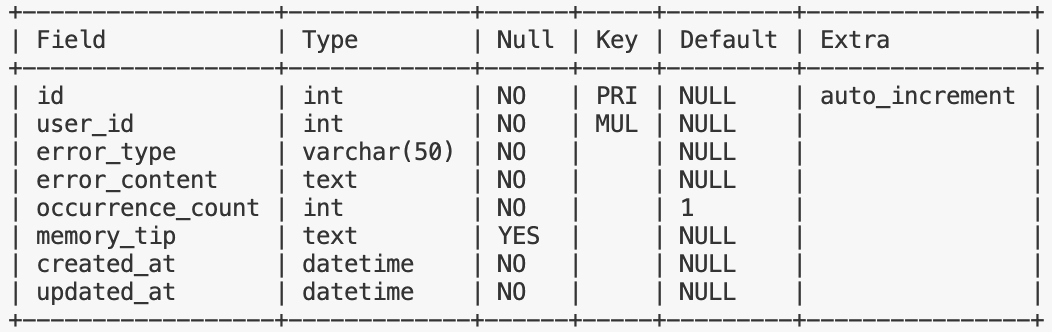
查询高频错误:
针对 user_id 和 occurrence_count 两个字段建立了联合索引,覆盖了 where 和 order by 条件,查询语句如下:
SELECT * FROM recitation_error_pattern
WHERE user_id = ?
AND occurrence_count >= 2
ORDER BY occurrence_count DESC;
recitation_review_schedule —— 背诵复习计划,基于艾宾浩斯曲线的复习管理,记录每段内容的首次达标时间、后续复习时间、复习次数、上次复习准确率和复习间隔时间等信息,用于生成个性化复习计划
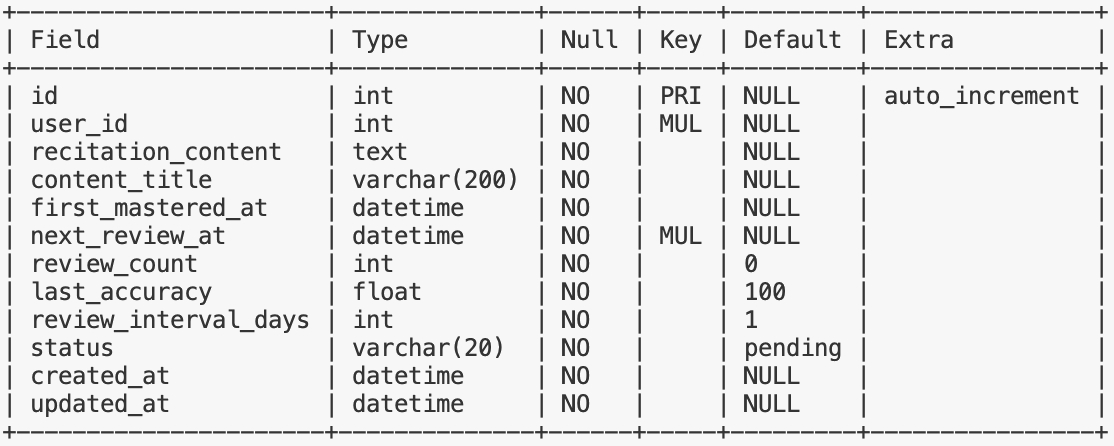
查询待复习列表:
针对 user_id、status 和 next_review_at 三个字段建立了联合索引,覆盖了 where 和 order by 条件,查询语句如下:
SELECT * FROM recitation_review_schedule
WHERE user_id = ?
AND status = 'pending'
AND next_review_at <= NOW()
ORDER BY next_review_at;
recitation_report —— 背诵报告记录,存储生成的日报和周报内容,包括报告类型、报告日期、总背诵次数、平均正确率、背诵总结和薄弱点等信息
幂等:当天同用户已经生成的周报/日报不会重复生成,而是覆盖更新
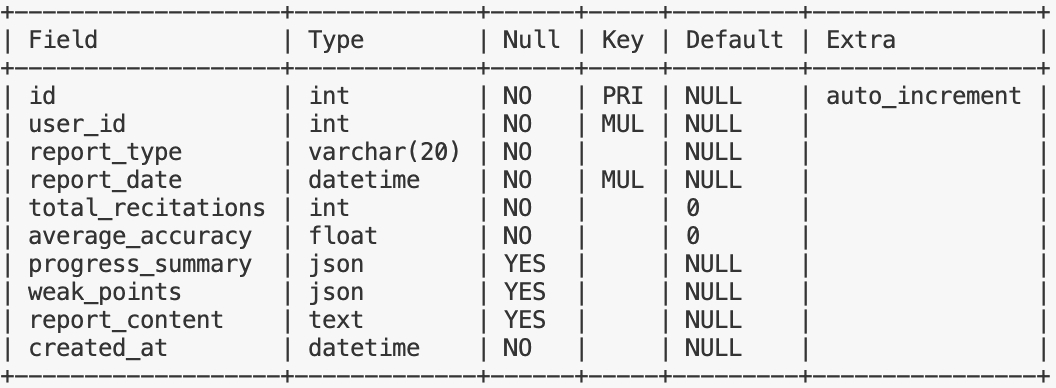
查询指定日期报告:
针对 user_id、report_type 和 report_date 三个字段建立了联合索引,覆盖了 where 条件,并建立了唯一索引防止重复生成报告,查询语句如下:
SELECT * FROM recitation_report
WHERE user_id = ?
AND report_type = 'daily'
AND report_date = '2024-01-01';
背诵场景下一对多的关系是比较常见的,一个用户可能会有多条记录,针对不同的具体内容拆分出了共四张面向不同功能的数据表
History → ErrorPattern 是间接关联,背诵检查会得到 errors 并写到历史记录中,再被同时更新到 ErrorPattern 中
History → ReviewSchedule 是条件关联,只有首次背诵达标,即正确率大于等于 85% 时才会创建复习计划
History + ErrorPattern → Report 是聚合关联,先查询当天的背诵历史,然后查询高频错误,再结合生成日报/周报
索引使用效果对比:
| 查询场景 | 无索引平均响应时间 | 有索引平均响应时间 |
|---|---|---|
| 查询背诵历史 | 约 100–150ms | 约 30–40ms |
| 查询高频错误 | 约 120–160ms | 约 40–50ms |
| 查询待复习列表 | 约 120-140ms | 约 30–40ms |
| 查询背诵报告 | 约 100-120ms | 约 20-30ms |
2.3.2 状态设计
用户输入(触发事件) —— 编排器识别背诵意图 —— 进入背诵 agent 工作流 —— 返回结果
背诵 agent 工作流:
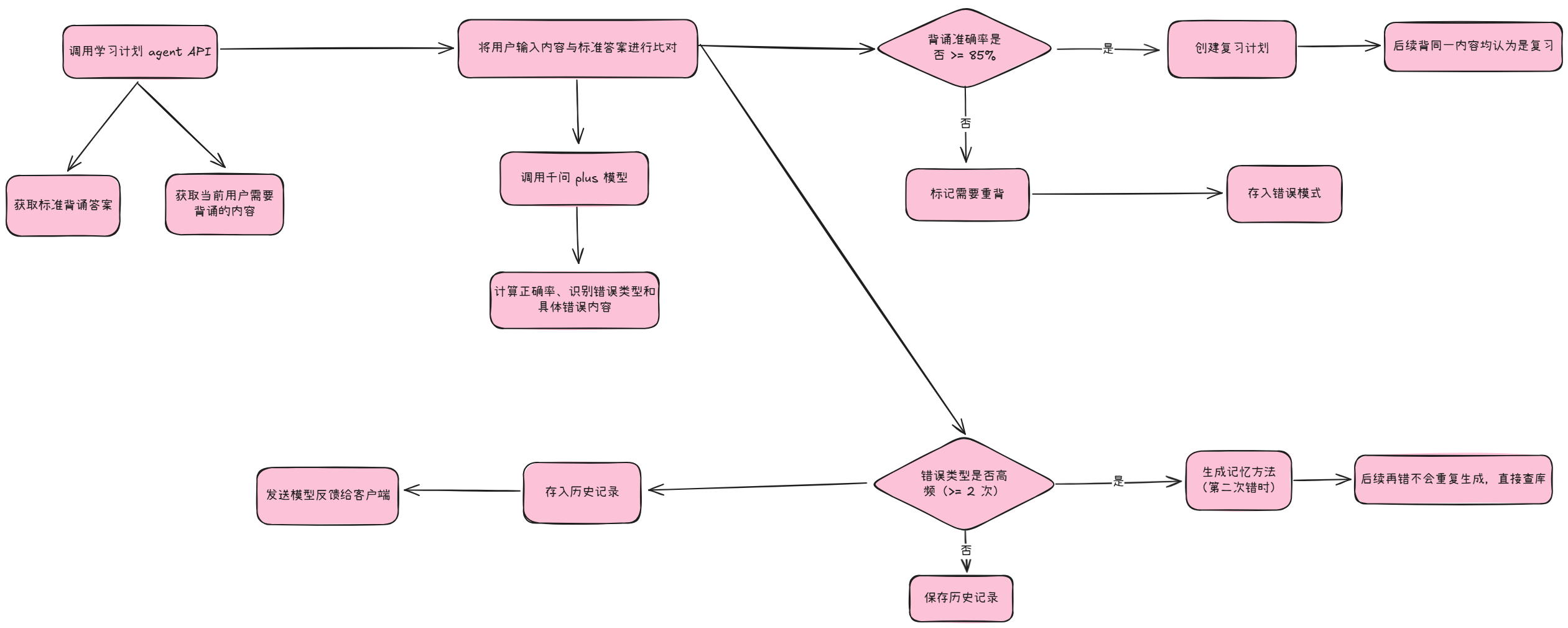
2.4 算法与 LLM 逻辑
在 LLM 失败或 JSON 解析错误时,会把准确率设置为 0, 当前的兜底逻辑就是直接报错信息提示用户重试,错误信息明确为解析失败,无论成功还是失败都会在 finally 里恢复状态
2.4.1 准确率计算
背诵内容主要是古诗文和英语课文,这时每个字都挺关键的,并且背诵常见的错误就是漏字、错字和顺序混乱什么的,按字统计能更细致反映掌握情况
字符级的对比算法实现简单,按词或者句分隔在不同场景下不稳定,容易受到标点、语气词等影响,并且错误分布也会更均匀,家长和学生也更容易理解,于是就采用了如下公式:
准确率 = (正确字数 / 总字数) * 100%
2.4.2 LLM 调用合并与记忆方法生成
最初设计时,背诵 agent 分为两个子任务:检查比对和鼓励反馈,分别调用 LLM 进行处理
这造成了下面的问题:
- 延迟高:两次网络往返增加了响应时间
- 成本高:两次调用都需要传递完整的上下文,token 消耗翻倍
- 用户体验差:学生等待时间过长,影响学习节奏
于是后续做了合并,一次调用同时完成检查和鼓励的逻辑,并一次性返回检查和鼓励的结果,在内部构造的 50 次背诵测试中,调用平均延迟降低了约 2s,token 消耗从 ~1200 降低到了 ~700
只有在第二次重复错时才会生成针对这个错误的记忆方法,后续再次犯这个错误时也只会从表中读取记忆方法,而不会再调用 LLM 生成
2.4.3 错误分类策略(规则 + 模型结合)
两种方案:
- 方案 A:让 LLM 分类
- 每次都调用 LLM 判断错误类型
- 准确率高,但延迟高、成本高
- 方案 B:基于规则的算法
- 对于可预测的错误类型,设计规则进行分类
- 比对
expected和actual两个变量的内容- 漏内容:actual 为空或明显短于 expected(50%)
- 字音错:长度相同,只有个别字不同(2 个字)
- 记混顺序:内容相同但顺序不同
- 准确率稍低,但延迟低、成本低
由于背诵场景中错误类型相对固定且可预测,最终选择了两个方案结合
2.4.4 错误智能去重迭代
同类型的错误可能以不同的形式出现
V1:最开始的去重方案是简单的字符串匹配,只有完全一致才判定重复,测试发现会收到标点符号和空格的影响
V2:增加了标准化处理,去除标点和空格,但会受到同样一个错误因为出现在不同的上下文中而无法去重的问题
V3:选择了提取核心词对比 + 子串包含的方式,在标准化的基础上,对已有错误进行查找,允许子串匹配
先在数据库中精准匹配,查询某个用户某个类型的所有错误,再在应用层做模糊匹配,在更新或创建时使用乐观锁避免并发问题
最近测试发现可能是因为提示词设计矛盾,对于其输出的:
{
"agent_id": "recitation_99191857",
"user_id": 1,
"accuracy": 50,
"need_retry": true,
"feedback": "准确率50%,前两句很好,但遗漏了第3、4句,完整背一遍试试\n\n漏内容(第2次): 登高望远见山河,不更上怎见一层楼。\n漏内容(第2次): 登高望远见山河,不更上怎见一层楼。",
"errors": [
{
"position": "第3句",
"expected": "欲穷千里目,更上一层楼。",
"actual": "",
"type": "遗漏"
},
{
"position": "第4句",
"expected": "更上一层楼。",
"actual": "",
"type": "遗漏"
}
],
"usage": {
"qwen_plus": {
"input_tokens": 828,
"output_tokens": 116,
"cost": 0.0009
}
}
}
LLM 会对同一个错误重复计数,优化后解决了,具体是将提示词中的错误定位规则里关于 position 字段的定义从只能使用第几行改为了允许动态修改,具体到第几行第几个字,从而抛弃了原本的只有第几个字的错误
2.4.5 基于艾宾浩斯的复习计划
区分了首次背诵和复习背诵,只有首次背诵准确率达标后,才会创建复习计划,达标后后续的背诵都默认是复习,只要是复习,如果准确率不达标就会缩短下次复习计划时间,达标的话就延长
并不是一定要到了下次计划的复习时间才能再次背诵,如果首次背诵没有达标,会提示要再重新背一次
2.5 工程实现与评估
2.5.1 代码结构与分层
- 接口层
- api/recitation_router.py
- 定义 HTTP 路由,处理请求和响应,RESTful 风格
- 依赖注入,调用服务层
- 统一的异常处理和响应格式
- api/dto/recitation_dto.py
- 定义请求和响应的数据传输对象(DTO)
- api/recitation_router.py
- 服务层
- service/recitation_service.py
- 核心业务逻辑编排,协调各个组件完成背诵功能
- 获取背诵内容、调用 LLM 进行背诵检查、错误分类和记录、记忆方法生成、复习计划和报告生成等逻辑
- service/task_manager.py
- 任务管理,支持同步和异步任务执行
- 任务状态跟踪和结果存储
- service/recitation_service.py
- repository 层
- repository/recitation_repository.py
- 数据库操作封装,使用 SQLAlchemy ORM 进行增删改查
- 只负责数据访问,不包含业务逻辑,参数化查询,防止 SQL 注入
- 异步操作支持,提高并发性能
- repository/error_pattern_repository.py
- 智能去重记录错误,更新错误频次和记忆方法
- 原子操作,查询和更新在一个事务中
- repository/review_schedule_repository.py
- 创建、更新、查询复习计划
- 根据准确率自动调整复习间隔
- repository/report_repository.py
- 聚合计算日报/周报数据
- 幂等生成报告,避免重复创建
- 历史报告查询
- repository/qwen_repository.py
- LLM 调用封装,统一管理模型调用逻辑,调用 Qwen-3 Plus 模型
- 异步执行,JSON 格式输入输出处理,自动计算 token 使用量和成本
- repository/recitation_repository.py
- 模型层
- model/recitation_orm_model.py
- 定义数据库 ORM 模型类,映射到对应的数据表
- model/recitation_orm_model.py
- 提示词层
- prompt/recitation_prompts.py
- 提示词模板构建函数封装
- prompt/config.json
- 存储提示词模板和配置参数,支持多场景和多模型
- prompt/recitation_prompts.py
2.5.2 扩展性与未来改进
假设场景: 小学生每天背诵
- 每天背诵次数: 5次
- 每次错误数: 平均3个
- 每周生成报告: 1份日报 + 1份周报
一年数据量:
- RecitationHistory: 5次/天 × 365天 = 1,825条
- RecitationErrorPattern: 去重后约 20-30种高频错误
- RecitationReviewSchedule: 累计背诵50篇课文 = 50条
- RecitationReport: 365份日报 + 52份周报 = 417份
单用户总数据量: ~2300条
单条记录大小:
- RecitationHistory: ~1KB (包含JSON字段)
- RecitationErrorPattern: ~200B
- RecitationReviewSchedule: ~300B
- RecitationReport: ~2KB (包含JSON字段)
10 万用户存储:
- History: 1.8亿 × 1KB = 180GB
- ErrorPattern: 300万 × 200B = 600MB
- ReviewSchedule: 500万 × 300B = 1.5GB
- Report: 4000万 × 2KB = 80GB
总存储: ~262GB (未压缩) 压缩后: ~100-120GB
用户数量上来后,可以按月归档冷数据,保留最近三个月的热数据在主库,历史数据归档到备份库,分库分表,按功能模块垂直拆分,读写分离,写操作走主库,异步刷新缓存,读操作走从库,redis 做缓存
3. 其他
3.1 HTTP 自调用问题
3.2 Alembic 迁移工具重新启用与优化
重新启用 Alembic 迁移工具,解决现有脚本在不同环境不同机器部署时出现的问题,优化项目 Readme 启动项目步骤中数据库相关指引流程
场景
做了什么
结果
3.3 监督 agent 提示词优化与识别准确率提升
优化监督 agent 提示词,提高监督 agent 的识别准确率,解决实际运行中出现的误判问题(待量化数据)
3.4 聊天 agent 接入主 agent
将聊天 agent 接入主 agent,使得聊天 agent 不再独立对外暴露接口,由主 agent 统一调度(小幅度重构)
3.5 客户端语音播放逻辑优化
优化客户端语音播放逻辑,用加全局锁的方式解决语音播放冲突和打断问题(相对跟后端关系不大,或者可以包装一下)
后端技术栈
-
编程语言:Python
-
框架:FastAPI
-
数据库:MySQL
- ORM:SQLAlchemy
- 迁移工具:Alembic
-
缓存:Redis
-
接口文档管理:Swagger
-
代码评审和项目管理:GitHub